
ni includes all the basic tools required to stream compressed audio into a binary reader, export samples, and stream batches of those into NumPy for windowed FFT processing. Those can be visualized directly in the web UI.
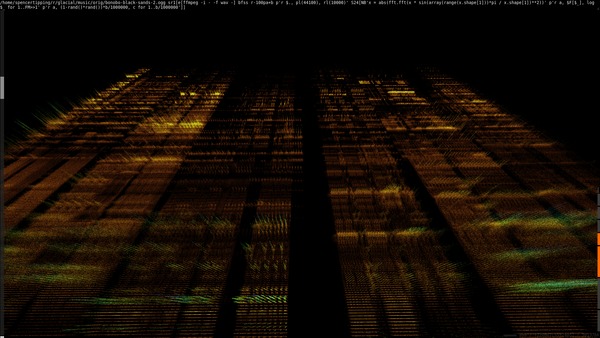
This one completely surprised me. I was looking for the exact spacing being applied to some data and started seeing all kinds of interesting stuff in the high-frequency range: spikes at 217 and 218 indicating single-precision truncation, powers of ten indicating digit truncation, and in another (not yet published) analysis, 1/60 and 1/3600 from truncated DMS encoding.
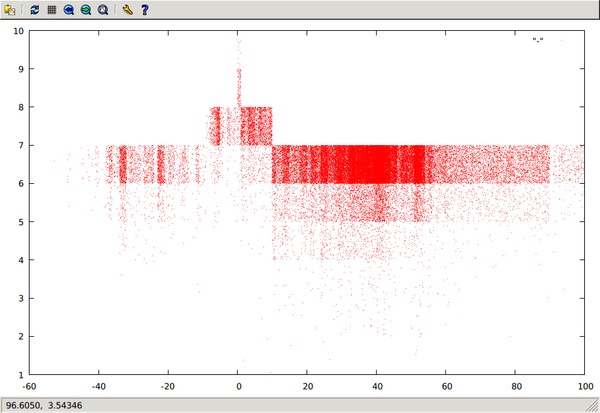
How to produce a YouTube video of OSM's full history starting with the planet download. Uses gnuplot, ffmpeg, ImageMagick, and ni.

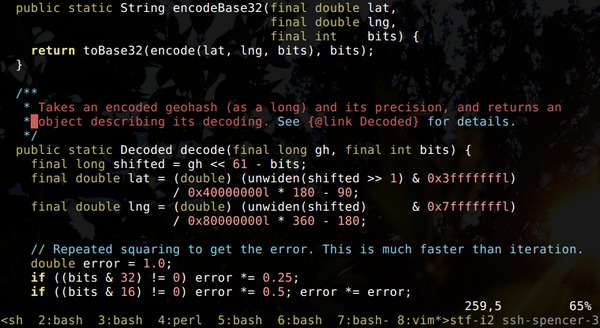
I wanted a data analysis tool that leveraged UNIX process pipelines, could install itself using an SSH connection, and that could visualize arbitrarily large data and remain responsive. So I wrote ni.
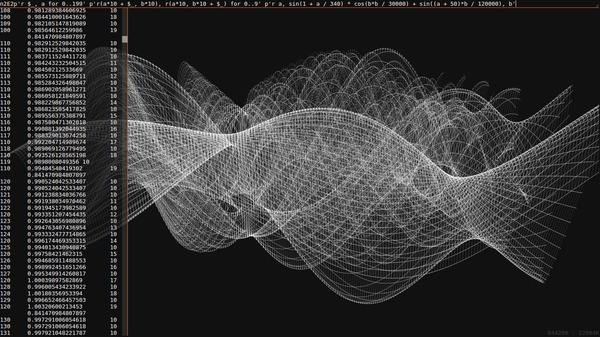
Once I added git:// accessors to ni it was only a matter of
time before I started looking into commits as data. I have a much larger
project about this in the works, but these are some preliminary results.
A look at the link structure, trends over time, and general processing for Wikipedia's full history using ni.
Looking for patterns of behavior that would indicate that a set of users are acting in tandem.
A ni-based workflow to shard OSM by geohash tiles, then visualize and efficiently render historical uploads for a given city or region.
ni is a much more powerful version of nfu, a Perl script I wrote to shorten command-line data queries. ni inherits a lot from nfu, including the central pipeline mechanics and concatenative syntax.
A fairly comprehensive look at the types of things you can do with nfu and
command-line streaming tools in general. I still use nfu for some of these
things, particularly interactive gnuplot.
SRTM1 is a one arc-second resolution heightmap you can download in an efficient binary format. I used ni's binary operators to repack the tiles into a more usable geometric format to make it easier to visualize the full planet.

What looked at first like a sloppy ad fraud attempt ended up revealing an interesting bug in the way the data was generated; that helped us build a faster classifier for it.
ni --js deadline renderingDynamic adjustment for varying CPU throughput to preserve overall luminosity, while also maintaining a 30ms rendering deadline.

A quick tutorial that covers the basics of writing a UNIX shell, along
with related background (e.g. fork, exec, and
file descriptors).

This was a terrible idea that ended up being really cool. I used a bunch of these objects as data containers for various projects before finally switching to a more traditional development style years later.
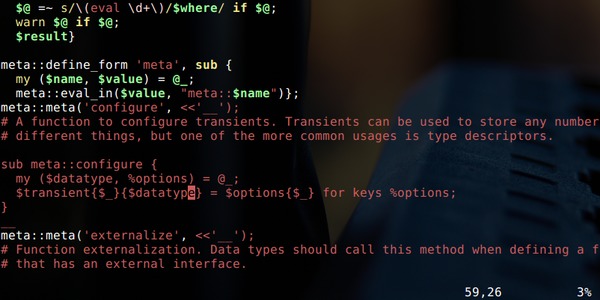
This started as a weekend replacement for a proprietary library about ten years ago, but ended up accumulating a bunch of interesting features like turtle forking, 3D coordinate systems, triangle rendering, etc.

A lot of people assume that JIT compilers are complicated, but the core mechanics of writing one are surprisingly straightforward. I wrote up a short tutorial that covers the basics in C.
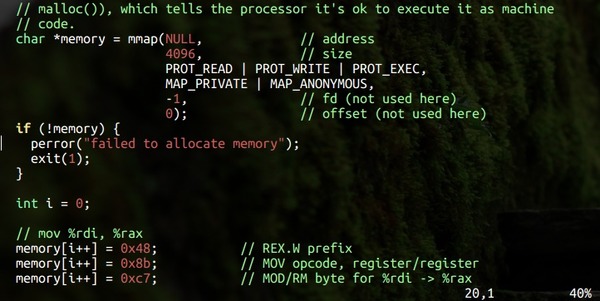
A fairly quick introduction to randomness, entropy, and data compression
fundamentals. If you want to know the difference between gzip
and ppmd or what arithmetic coding is, this is the guide for
you.
This format ended up being more trouble than it was worth, but I used it for a number of years. This was the project that got me into the habit of writing literate code, something I still tend to do if the language has adequate block comment support.
A writeup that describes step-by-step how you would construct a self-modifying Perl script and why you might want to.
A blog post I wrote while I was working at Factual, discussing some considerations for constructing fast data pipelines. A look at assembly and some libc functions from a scripting perspective.
This is the system I use to generate the unit tests for ni. ni's documentation is written in Markdown and contains examples of interactive shell sessions, which lazytest then converts into a shell script to verify that it behaves as advertised.
This is an old project, but a lot of fun. I was interested in writing a
simple concatenative language based on Joy that had enough expressiveness
to build up to something like Lisp or Scheme. On a minimalistic streak, I
decided to write it in x86-64 machine code using a not-quite-assembler I
had written in Perl. The reader has a bug that prevents it from working,
but the design is workable and does some interesting stuff like using
machine code to represent data structures; that way eval is
simply a jump instruction.
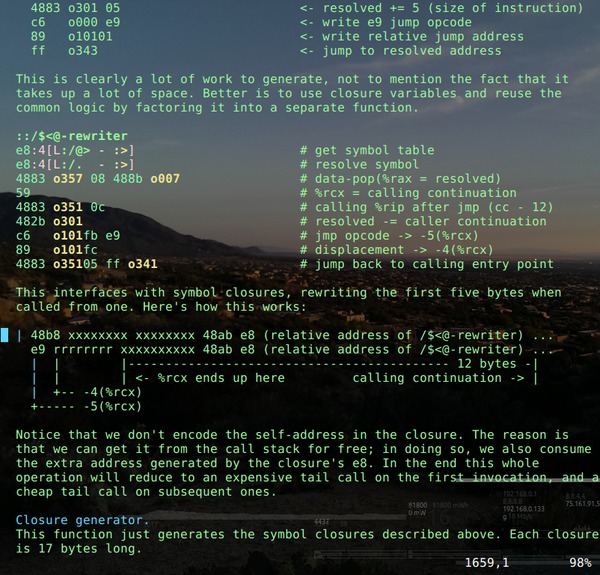
An interesting way to sort a list of objects by a list of doubles, without using any custom comparators or value boxing. A good hack to know about if you're writing performance-sensitive code.
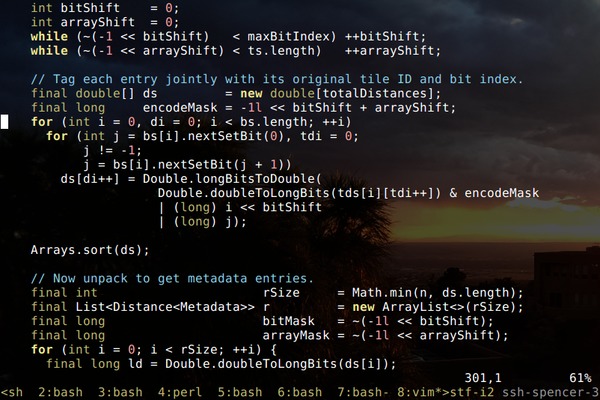
A lot of the overhead of geohash encoding can be eliminated using Morton encoding and some float/int casts.
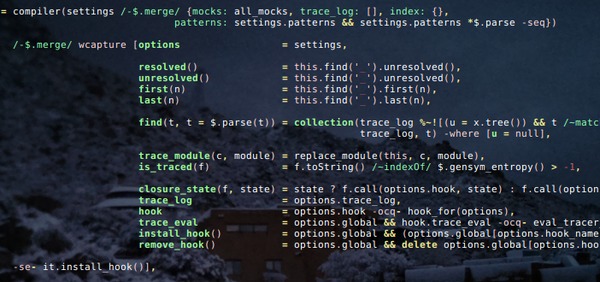
Javascript functions provide a .toString() method that
returns their source code in string form. Caterwaul uses this to parse,
transform, and recompile your code, adding arbitrary Lisp-style macros as
well as its own standard library.
This was a fun project: it would rewrite your code to track the evaluation of specified expressions, logging the results into a searchable data structure you could then query.
When I wrote this, it was faster (in CPU terms) than serializing floats into JSON; since then v8 has improved and Flotsam is nowhere near competitive. Flotsam was useful, though, because its output could be dropped into JSON without generating very many escaped characters.
A library that can handle circular references and other such data, resulting a base-94 string that can be packed 1:1 into JSON (i.e. it avoids JSON-escaped characters). I later used a similar format for Flotsam, a floating-point serialization format also written in Javascript.
With Infuse, xs.map(f) returns a value that itself will
update if you subsequently append entries to xs. This was
challenging to write because it's easy to create space leaks and other
pathological behavior when you're tracking object modifications. I never
used this project in production, but learned a lot putting it together.
One of my first attempts to write a visualization layer for data too large to fit into memory. This library had some cool ideas, and I ended up using it at Factual to visualize large clusters.
This was years ago, but still a cool project and simple to implement. It's based around a node.js server that sends work to clients, collects the results, and returns them to the job-runner page. May be of interest if you need to write a raytracer in Javascript for some reason.

The big idea behind this project was to replace things like Hadoop with something hosted in bash, using SSH and other UNIX tools to process big data in a distributed way. Predictably, it never reached that level of utility; but I think this is still the only concurrent garbage collector written in bash.
The now-infamous guide I wrote years ago, and which I'm sure is no longer current. I can't vouch for its quality or brevity, but it's my most popular Github project to date.

I used to use sha256sum on every file to find duplicates,
but it turns out to be a very slow approach for most real-world
filesystems. Quickdupe uses the fastest accurate algorithm I know of, in
many cases avoiding file reads altogether.

Conky is great, but by default it lays everything out using text flow rather than absolute coordinates. I wrote a Perl script to let you insert absolute and relative offsets into your conkyrc to get arbitrary positioning for each element.
zsh users are understandably fond of right-hand prompt indicators, but it turns out that you can do the same thing in bash with a bit of escape character trickery.
sshfs, encfs, and FUSE in general are great tools, but managing the
mountpoints is more trouble than it could be. I wrote a new
cd function for bash that does this for you, and supports
custom overloading so you can add your own extensions.
This is one of the things I can't live without: anytime I SSH into a
system, I get dropped into a persistent tmux and xpra. This way both
terminal sessions and X applications survive beyond the active
connection. xpra is also much faster than ssh
-X.
A rundown of open-source infrastructure I run on the servers (and some public EC2s).
Basically the dumbest possible way to monitor stuff. It has problems and doesn't scale, but it gets the job done for now.
A sort of cool metaprogramming structure? Nothing that redeems the project, though.
A project even worse than Motley. I don't use it anymore.
eBay makes it possible to build a very powerful home computing setup on a small budget. This writeup covers some of the issues I ran into building a datacenter from used rackmount equipment.

Using ImageMagick to automatically generate thousands of randomized wallpapers from photos and scans of handwriting. This went better than I thought it would, and ended up being surprisingly easy.

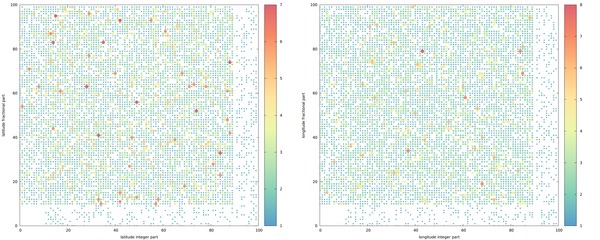
GPS error isn't random, particularly for cost-optimized receivers like the ones in cell phones. This writeup involves heading up to the roof to build a horizon profile, then tracking each satellite over time to match observed inaccuracies.

A functional JIT-compiled language with a computed grammar, written in machine code. It borrows elements from Lisp, FORTH, and Smalltalk. Hoping to ship this end of 2018.
An unfinished project that replaced the syscall instruction
with a two-byte illegal instruction, then trapped SIGILL to
provide virtualized behavior. I didn't know about vsyscalls when I
designed this, nor did I realize that most people solved the problem by
preloading a libc wrapper.
An attempt to build detailed 3D models of cities from youtube footage of people driving through them, in this case starting with Manhattan. Uses ni to unpack streaming video frames, and PDL to do FFT phase correlation of image tiles.
make for bashAn early attempt to provide file-based dependency management to bash. More design than reality; I ran into some fundamental problems with the approach, as well as egregious performance issues with bash arrays (which I think have since been fixed).
An unfinished project before I understood how difficult it would be to
implement, and before I realized that chaos_pp and
order_pp existed.
A work in progress; I don't quite understand electrodynamics well enough to get the math right yet.
Audio and trilateration for precise cell phone positioning. This unfinished project goes through a sonar transmitter design, how to code it on an Arduino, and the engineering required to optimize the carrier frequencies for maximum accuracy.
Looking for ways to exploit the nonuniform distributions of polygon edge lengths and angles.
A hackathon project with Chris Bleakley that involved tracking the satellite's position, correcting for drift, and using the Factual dataset to match bright spots with real-world places to figure out the exact camera angles. Writeup pending...

This one is mediocre, but it could be the start of something amazing. It's heavy, requires tools to refill, and makes it past TSA with no problems at all. Full writeup pending when I build the next one.

I missed the climbing wall at Google, so I got a bunch of lumber and built one in the living room.
This was one of my first Arduino projects. It used an R2R DAC and split each of three port registers across both channels so there would be no timing difference. That's where its virtues ended though; because you can only write to one port register per cycle, the signal contained 125ns distortions and it could only emit about 1MS/s. It also had clipping issues due to the op-amp voltage margins. Postmortem pending...

I didn't expect this to end well. It turns out that laundry rooms have some downsides as datacenters, one of which being that servers get soggy if things go wrong. A hot shower and some isopropyl alcohol later, this machine was up and running again.

New Mexico has a desert climate that makes it possible to use evaporative, rather than refrigerated, air conditioning. The energy efficiency is awesome, but the control system leaves something to be desired -- so I made my own. Writeup pending...

I found it on eBay for $35, untested and "probably not working." It turned out to be in unexpectedly good shape: two channels worked normally and the other two were partially working but had some major attenuation and distortion going on. Writeup pending...

A pre-lathe turning project.

Wood stoves may be elegant, but they're a lot more expensive than iron pipe, sheet metal, and a mini Shop-Vac. They're also a lot quieter. Writeup pending...

Writeup pending...

Not the best design, but cheap and precise after some tuning. I used a circle saw and router to cut the plywood, then 3/16" aluminum bar stock for the guides. Writeup pending...

Evaporative coolers require a lot of maintenance, and I like having roof access in general. So rather than dragging out the regular ladder, I built one onto the side of the house using some old deck wood and carriage bolts. Nothing is permanently mounted; the top is held in place with a wooden lever clamp and the weight is transferred straight to the ground. Writeup pending...




